
我理解的移动互联网是“屌丝”的时代,目前35%移动互联网用户的收入在两千元以下,属于主流用户人群。那移动互联网的核心是什么?我认为,形成了一种全新的人与人之间的关系人群链,人群关系组织特征体现为社交、本地、移动、个性。
看看现在的互联网用户,按月度来看,目前视频是第一大互联网应用。中国人现在平均每天消费视频的时间2.5个小时,你最宝贵的黄金时间段都浪费在视频上。但是我们目前最后的一块屏幕,实际上还没有被互联网化,是一个体验最糟糕的屏幕,这就是电视机。
所以,每个用户花费时间越长,就有更多机会做商业化,互联网思维本质是从用户出发,首先抓的是有没有覆盖很大的用户人群,第二用户群黏性是不是很高。
目前访问频次最高、时长最多的是视频应用,社交网络、电子商务、微博、网络游戏,依次排下来。这基本上也是互联网公司PK的标准。
那互联网公司怎么算估值,实际上至今也没办法算,推特日前在美国上市,连盈利模式都还没有;包括PPTV今天还是亏本,估值怎么算?资本界一般参考用户数量,比如一个用户按三十美金算,目前PPTV每个月有3亿用户,平均每个人每天的使用时长差不多2.5小时。可以算算这个人的价值有多少?基本上所有的互联网公司都想提供一种服务,使得用户使用时间黏度越长,就能找出变现机会。
趋势一:从信息服务走向生活体验服务
当前,互联网已从信息服务进入生活体验服务。
移动互联网到今年6月,第一波算结束了,基本上用两年半时间,走完了PC互联网八年的路。我们认为到6月,移动互联网基本的大格局之战将结束。后面看谁还有创新,谁还有特别强的产品。反正基本上人类能想到的东西,已经都干了。所以移动互联网的机会不多了。
趋势二:互联网线上走向实体
互联网现在已经开始进入实体。传媒行业、零售行业、金融行业、制造行业,这四个行业是目前正在颠覆的,还有很多行业慢慢在颠覆。现在不提做广告了,电子商务开始大规模的向线下进军,都开始建物流渠道。我认为,电商公司未来一定会开实体门店,小米手机已经在四个城市开门店了。视频公司像PPTV,本来是买东西来给大家看,现在也拍了13部电影、电视剧;旅游公司以前是卖门票,现在全都在开发自己的景点。我估计,携程未来还要买酒店。他们比实体有一张好牌,大量的用户规模,而且忽悠用户的能力非常强。
趋势三:软硬结合生态系统的建立
以前互联网人写软件,现在我们公司最缺的就是做硬件的人,或者拍电影的人。所以现在软硬结合,是互联网玩的手法,不仅做软件,还做硬件。就像雷军所说,订单已经足够了,现金流更从容一些,先拿订单再生产,而且个性化定制。
互联网的本质:
1、用户第一
去中心化,挑战传统权威,去产品化,不卖产品卖服务,去中介化,打破信息不对称。
可能在三年之内,电视机可能会免费,有人会跑到你家给你装电视机,现在这机顶盒马上快要免费了。为什么呢?因为发现要真正获得一个用户,黏度很高的用户,我们的成本超过100块元人民币一年。现在小米在做一个产品叫网关,就是家里那个无线上网的WIFI,大家经常说我那个WIFI好像不好,现在说我送给你一个。那里头带一个大的硬盘,那个硬盘就把你家里变成了一个大的计算机机房,一个数据中心了。
所以互联网思维就是不卖产品,只要是觉得能亏得起的话,那就上。最后就是去中心化,挑战一切的权威,这是互联网的一种打法。
还有一个要命的东西,主流用户人群不给你机会讲道理。如何忽悠屌丝阶层,他们手上存款总共才几百块人民币,到银行也没人理。阿里巴巴余额宝说,来来,五百块放到我这儿,利息比银行还高,而且很简单。我们公司的员工基本上每个月都在余额宝里放上五百块钱、一千块钱,不算多。他也不会用它来买房子,但是阿余额宝有三千万的注册用户,一个人放一块钱就是三亿(最新数据余额宝的规模已达2500亿)。
2、从群众中来,到群众中去
互联网服务客户,不管是男女是老少,统统都要,只要是用户。他首先服务的是那帮屌丝,也就是当时毛主席说的,到农村去,到工人阶级里去。移动互联网更加糟糕,为什么?碎片化跑来了,用户时间很少,被忽悠的可能性太大。在中国互联网基本没有规则,我的邮件信箱前不久还被进攻过。1.5亿跟江苏卫视买《最强大脑》节目,因为有合约不能做直播,怕影响收视率。结果,其他几个同行同时在线直播,怎么办?1.5亿就白投了吗?中国互联网的玩法是很心惊肉跳的。
互联网的用户是屌丝,两个特征,贪婪和懒惰。你要解决这两件事,不仅要给他服务,免费他觉得不行,还要给他创造价值。怎样让这帮屌丝喜欢你呢?要让他成为你的粉丝,要对你有忠诚度,你要真正了解他。
3、抓住用户:星星之火,可以燎原
利用互联网的传播特性,并通过制造轰动性事件、争议性话题等,实现大范围病毒传播,乃至达致引爆点。培育和勾引死忠用户,壮大粉丝规模,营造粉丝文化乃至构建话语体系。
像雷军说的,要有人。小米手机卖799元,网上找不到这个性价比的手机,要么就是999元。两百块钱差在哪里?799的性能跟苹果手机一样,满大街也找不到,但是你可以去注册排队,偶尔抽奖拼运气,大规模买,不好意思没货,就像iPhone饥饿营销。这就是造势,还壮大了一大批粉丝群。
在互联网做也不容易,领导人要找到一个气质,符合特定的用户人群,找到机会,就要打。当用户被你忽悠进来,但是体验以后发现不好,还会走掉,这样就逼着你做出最核心的极致体验,逼着你创新,逼着你每天想,给他更多的超出预期,天天挖空心思想创新的事。
4、留住用户:全心全意为人民服务
什么叫极致体验呢?第一没有任何门槛,比如最近我让七十多岁的父亲用微信,他用得很高兴。第二超出预期,就像海底捞实体店,不是吃海底捞的东西,不打内容牌,打的是服务牌。
第三大数据,现在用手机打开PPTV的应用程序,每个人看的内容不一样。大数据可以解决个性化的问题。我们把3亿用户,按数据分成48个等级,分析哪一些是贡献多的,哪一些是不经常来的,想办法把他们抓回来。打造产品,要反复迭代,每天出奇,让用户参与,这是不容易做的一件事。
5、商业模式
免费做大用户规模:广告、电商和游戏;用户规模摊薄成本;大鱼吃小鱼和快鱼吃慢鱼;粉丝品牌打造溢价空间。
互联网三大经济基础,广告、电商和游戏。我们认为要达到过亿用户群,可以用广告很快地摊薄成本。比如买下电影《私人定制》独家版权,如果有一百万个人愿意付费,每人交五块钱,就是五百万的版权。如果免费的话,可能有五千万的人来看,跟广告主谈赞助,三千万行不行?一点问题都没有。当用户规模起来以后,可以把成本摊薄。
在互联网行业,最典型的是大鱼吃小鱼,快鱼吃慢鱼。大家都在争头几年的势头,再往后日子越来越难,越来越难做,因为互联网没有门槛。线下实体还好办,国美跟苏宁打了那么多年,门店对着开,但在互联网,用户的迁移成本是零。这也是互联网的版权之战,你抢了独家,我也得抢,所以大鱼吃小鱼比较明显。
目前中国的资本界不给力,腾讯、阿里巴巴、百度稍微有点财大气粗,能收的他们都愿意收。但是很可惜都没有拿到中国市场的资本红利。
免费做到最后生存的可能只有几家。如果不做免费,就做溢价空间,或用粉丝平台打造溢价空间,比较典型的就是苹果和小米,通过供求关系突出品牌。
6、企业组织
必须能快速反应:降低决策流程,扁平化;先开枪,后瞄准的战术;需要犯错,容错力强;人员游动,内部竞争;
中国目前99%的企业仍然是传统行业,未来所有行业都会拥抱互联网。
互联网有三种组织模式代表,第一种就是最早的竖状结构,汇报跑一圈,所以微软现在跑不动了。
谷歌用扁平化结构,要求一个VP管二十多人,基本上就是有一个汇报线,让这二十几人自己弄,故意管不过来。
第三种Facebook的网络化管理结构,感觉是非常乱的。但在乱中,适应用户。这实际上是非常大的挑战,围绕着你的自己的商业模式和使用人群在变。
互联网团队是先开枪,后瞄准,实际上有脑子的人不会这么做。但为什么要做呢?强调决策观,团队里头必须要有人去犯错误,这是互联网的方式。
最后因为竞争激烈,互联网公司正常的员工流动性为25%,也就是四年公司人全部换一遍。这肯定是远远高于传统企业的,也不是坏事,同时鼓励内部竞争。经常两个团队PK一个产品,或者一个产品两个团队做不同的版本,就是要鲶鱼效应,内部进行PK,整个池子都活起来。


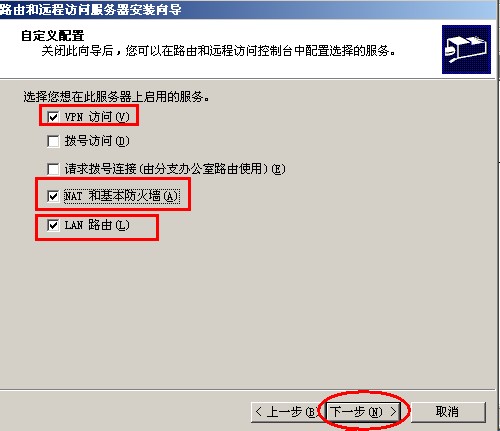
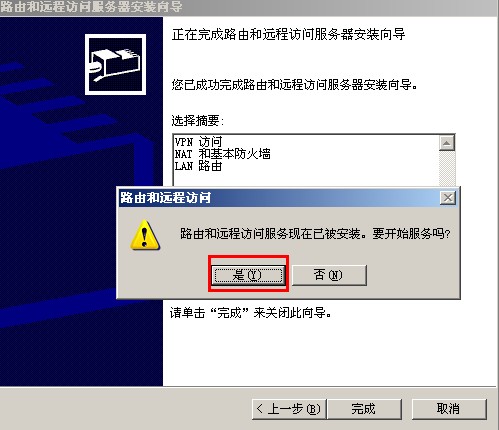
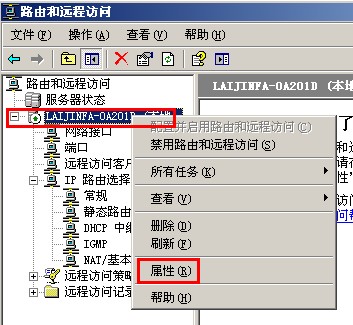
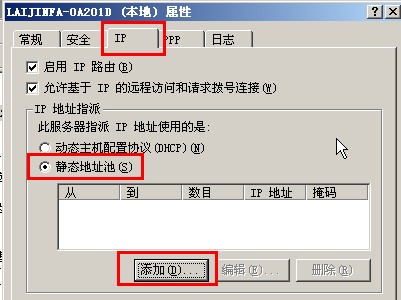
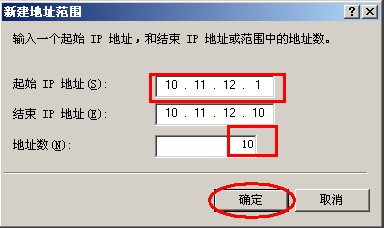
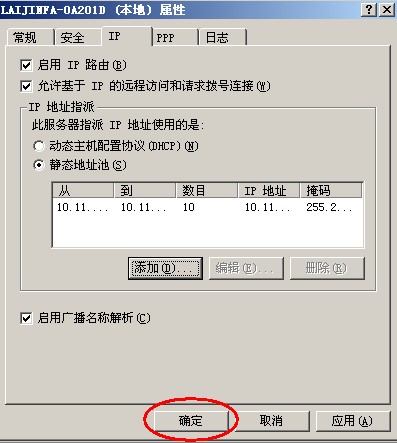
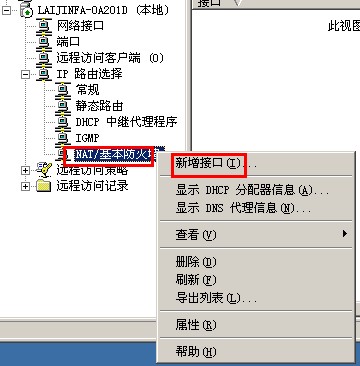
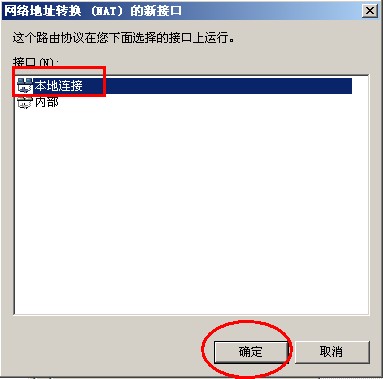
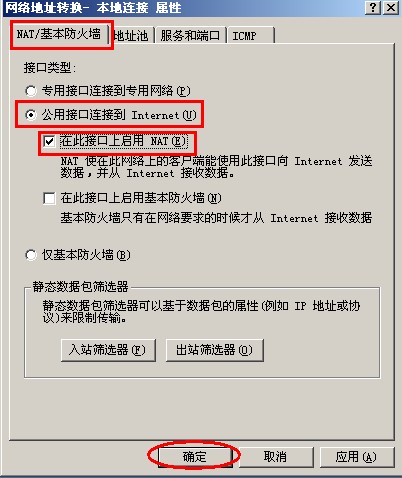
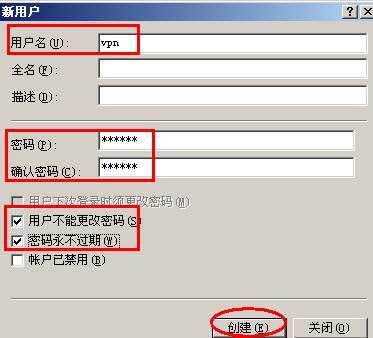
{kind=link}